Explaining AI Scene Generation for Immersive Storytelling

By The WaifuGen Team · Published June 2026
Most people still picture AI image generation as a one-shot deal: you type a prompt, you get a picture. That mental model is about three years out of date. Explaining AI scene generation today means covering a technology that builds spatially consistent 3D worlds, maintains character identity across dozens of frames, and renders explorable environments in real time. This article breaks down the core tech, the creative techniques, and the real workflows that creatives and developers are using right now to produce genuinely immersive AI visual storytelling. No hand-waving. Just the actual mechanics.
Table of Contents
- Key Takeaways
- Explaining AI Scene Generation: the core technology
- From flat images to explorable 3D worlds
- Character and object consistency across scenes
- Practical applications in 2026
- My take on where this is all heading
- See it in action on Waifugen
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Beyond static images | AI scene generation now produces navigable 3D environments, not just single images or short video clips. |
| Hybrid models lead | Transformer-diffusion architectures like Transfusion reason about composition before rendering pixels, improving accuracy and complexity. |
| Character consistency is solvable | LoRA fine-tuning achieves 85-95% feature retention, making persistent characters across scenes a real workflow option. |
| 3D Gaussian Splatting matters | This rendering method unlocks real-time, explorable 3D scene output suitable for VR and interactive media. |
| Prompting is a craft | Structured, separated prompts (identity vs. scene) are the difference between coherent outputs and visual chaos. |
Explaining AI Scene Generation: the core technology
The foundation of understanding AI image generation starts with diffusion models. These systems begin with pure visual noise and iteratively remove it, guided by a learned understanding of what images look like. Each denoising step moves the output closer to a coherent image. It sounds almost paradoxical, but it works exceptionally well.
What has changed recently is how AI models think before they generate. Hybrid transformer-diffusion architectures enable AI models to reason about image composition and constraints before generating pixels, which dramatically improves their ability to handle complex scenes with multiple objects, spatial relationships, and legible text. The older pure-diffusion approach was essentially a very sophisticated pattern matcher. The newer hybrid approach is closer to a visual planner.
Here is what that means in practice for AI scene creation:
- Text conditioning via cross-attention: Every token in your prompt gets mapped to specific regions and features of the image. Cross-attention mechanisms control how much influence each word has at each generation step, which is why prompt engineering actually matters at a technical level.
- Resolution and object counting improvements: Hybrid models handle crowded scenes far better. Counting five distinct characters in a scene used to reliably break older models. It still challenges them, but the failure rate has dropped.
- Text rendering within scenes: Generating legible signs, speech bubbles, or UI elements inside a scene was nearly impossible with pure diffusion. Reasoning-enabled models now do this with increasing reliability.
- Multimodal transformer integration: Modern AI image generators combine diffusion with multimodal transformers for improved prompt understanding and higher output fidelity, especially for scenes with complex lighting or layered depth.
Pro Tip: Structure your prompts in layers: environment first, then lighting, then subject, then emotional tone. This mirrors how cross-attention processes token priority and produces more coherent scene outputs than front-loading character descriptions.
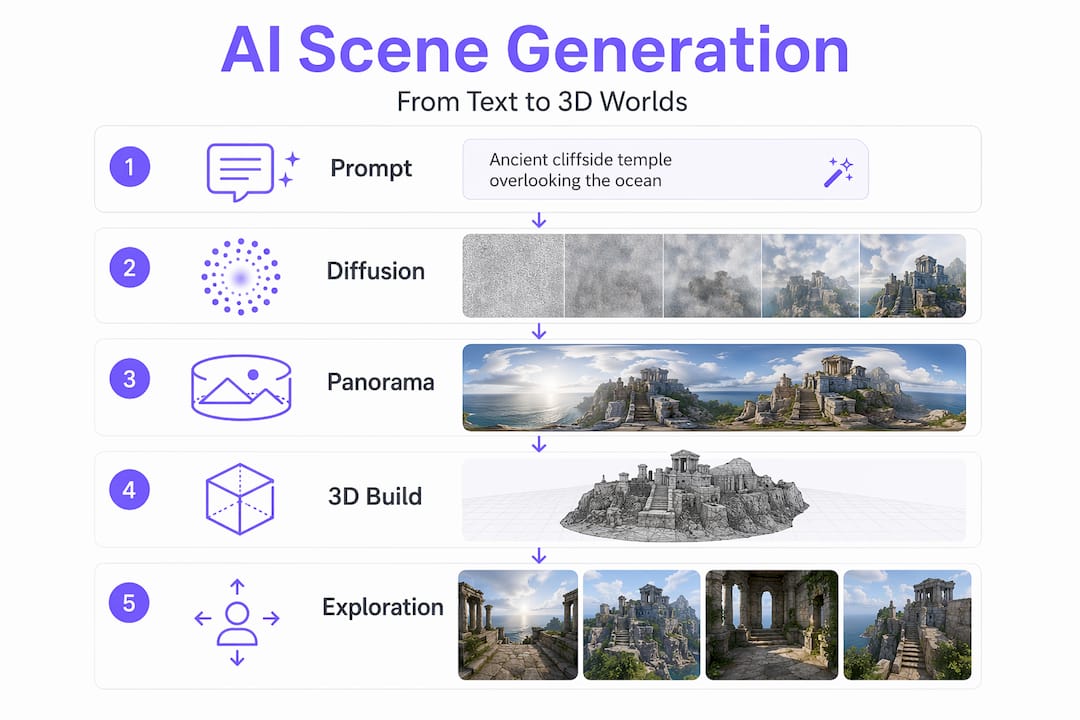
From flat images to explorable 3D worlds
This is where AI scene generation gets genuinely exciting for interactive media developers. The pipeline from a single 2D image to a navigable 3D world now has clear, reproducible stages. Hybrid 2D generative priors with geometric representations are the current direction for immersive 3D world generation, meaning AI is not abandoning its 2D strengths. It is using them as a springboard.

Here is how the technical pipeline actually breaks down:
| Stage | Process | Output |
|---|---|---|
| Panorama synthesis | AI expands a seed image into a 360-degree environment | Full equirectangular scene map |
| Depth estimation | Metric depth models lift the panorama into spatial coordinates | Depth-annotated image with real-world scale |
| Point cloud generation | Depth data is converted into a 3D point cloud | Sparse 3D scene skeleton |
| Inpainting | Point-cloud-conditioned models fill in unseen regions | Completed 3D geometry with texture |
| Gaussian Splatting | Scene is converted to 3D Gaussians for rendering | Real-time explorable environment |
The final stage deserves special attention. 3D Gaussian Splatting creates an efficient, explicit representation that allows generated scenes to be rendered interactively in real time, which makes it suitable for VR deployment. Unlike neural radiance fields (NeRFs), which require expensive per-view computation, 3DGS renders at speeds compatible with headset refresh rates.
Physics-augmented 3D scene generation pushes this further by producing physically stable, interactive environments in 10 to 30 minutes, faster than traditional manual scene design. For game developers or VR creators who previously spent weeks building a single explorable environment, that number is genuinely significant.
Video scene generation and persistent 3D world generation are two different beasts, worth distinguishing. Video clips give you a fixed camera path through a scene. Explorable 3D worlds let you move freely. Both have their place, but for truly immersive AI visual storytelling, the 3D route is where the creative ceiling is highest.
Character and object consistency across scenes
Here is the challenge nobody talks about enough: you can generate a stunning scene, and then generate the character in that scene, and they will look like completely different people. Character consistency is the hardest unsolved problem in practical AI scene generation pipelines.
The reason is structural. Diffusion models sample from a probability distribution each time they run. There is no built-in memory of who your character is. Unless you explicitly encode that identity into the model or the generation process, you will get a different interpretation of “red-haired girl with a scar” every single time.
The current solution workflow looks like this:
- Create a LoRA model for your character. LoRA fine-tuning achieves 85 to 95% feature retention, making it the industry standard for preserving a character’s visual identity across generations. You train a small adapter on 15 to 30 reference images, and it creates a callable token that pulls your character’s features into any new generation.
- Separate identity from scene description. Mixing “silver hair, amber eyes, school uniform” into the same prompt clause as “rainy rooftop at sunset” creates attention conflicts. Keep them in distinct prompt segments so cross-attention assigns the right weight to each.
- Use reference image conditioning as a secondary check. Some models accept a reference image alongside the text prompt. This is less flexible than LoRA but useful for one-off generations when you have not trained a dedicated character model.
- Apply structured inpainting for scene changes. Rather than regenerating the full scene when a character moves, mask the character region and regenerate only the background. This preserves spatial consistency without re-running the full pipeline.
General-purpose models struggle here more than specialized ones. If your AI visual storytelling project requires a specific character to appear consistently across 50 or 100 scenes, building a LoRA is not optional. It is table stakes.
Practical applications in 2026
The AI video generator market is projected at $847 million in 2026 with an 18.8% compound annual growth rate. That growth is being driven by actual workflow adoption, not hype. Here is where AI scene generation is creating real value right now:
- Rapid content creation: Standard AI video generators produce 3 to 12 second clips in under 60 seconds from text or image inputs. For social content, trailers, and mood reels, this is a practical production tool.
- Gaming and VR asset generation: Explorable AI scenes are moving into game development pipelines. Studios use AI-generated environments as blockout assets, refining them with traditional tools rather than building from scratch.
- ✍️ Interactive narrative experiences: Platforms building story-driven experiences are combining scene generation with character memory systems, creating environments that shift based on story state and user choices.
- Agentic scene editing: Emerging AI systems can accept natural language edit instructions after generation, like “make the lighting warmer” or “add a crowd in the background,” and apply them without regenerating the full image. This is a workflow shift from one-shot generation to iterative scene direction.
- ️ Animation pre-production: Animators use AI scene generation to produce storyboard panels, background plates, and color scripts at speeds that would have required entire teams a few years ago.
Pro Tip: Match your tool to your output format. For short video clips, text-to-video generators excel. For persistent VR environments, look for tools with 3DGS or NeRF export. For interactive narrative, prioritize platforms with character consistency features and scene state management.
AI-generated explorable assets are also changing how anime-style content creators approach world-building. Instead of commissioning dozens of background illustrations, creators can generate, iterate, and refine entire scene catalogs in a single session.
My take on where this is all heading
I have been watching the shift from diffusion-only models to hybrid architectures with real fascination. The ability to reason about a scene before rendering it is not a minor technical upgrade. It changes the fundamental nature of what AI generation can be. AI models with native reasoning transform image generation from an artistic tool to a design infrastructure component. That framing matters for how you build workflows around it.
What I have learned from watching creators struggle with these tools is that the model is rarely the bottleneck. The workflow is. People spend enormous time picking the “best” model and almost no time thinking about how to separate character identity from environment, or how to structure their generation pipeline for reuse. In my experience, a well-structured workflow with a mid-tier model beats a sloppy workflow with a top-tier model every single time.
I am genuinely excited about explorable 3D scenes over flat video generation. Video is a fixed path. 3D is a space. The difference for interactive storytelling is the difference between watching a movie and walking through a stage set. But I want to be honest about the current limits: real-time AI generation of novel viewpoints during live interaction is still not smooth or cheap. And global consistency across large explorable scenes (where objects move and lighting changes dynamically) remains a hard problem.
The lesson I keep coming back to is this: use AI to do the heavy lifting on the parts that would otherwise kill your momentum, and keep human creativity in the loop for the decisions that actually define the work. AI scene generation is most powerful as a collaboration tool, not a replacement for direction and taste.
— Roman
See it in action on Waifugen
Waifugen applies the techniques covered in this article to create something genuinely different: AI anime characters who exist inside dynamically generated scenes that match their mood, outfit, and emotional state in real time. The platform uses character consistency systems and scene generation to make each interaction feel like stepping into a living story. Whether you want to explore what AI character chat looks like with persistent memory, or you’re curious how scene generation powers an immersive anime companion experience, Waifugen is the place to see these concepts working together. Jump in and meet your anime companion to experience it firsthand.
FAQ
What exactly is AI scene generation?
AI scene generation is the process of using machine learning models to create coherent visual environments, including 2D images, video clips, and navigable 3D spaces, from text or image inputs. It goes far beyond single-image generation by producing spatially consistent, multi-element scenes.
How does AI generate scenes from text prompts?
Text-to-scene AI models use cross-attention mechanisms to map words in a prompt to specific visual features, guiding a diffusion or hybrid transformer-diffusion model through an iterative generation process until a coherent scene is produced.
Why do characters look different across AI-generated scenes?
AI models sample from a probability distribution on each run, so without explicit identity encoding, character features drift between generations. LoRA fine-tuning solves this by creating a persistent character token with 85 to 95% feature retention across scenes.
What is 3D Gaussian Splatting and why does it matter?
3D Gaussian Splatting is a rendering method that converts AI-generated scene data into a set of 3D Gaussians, enabling real-time interactive viewing. It is faster than NeRF-based methods and is becoming the standard for VR-ready AI scene output.
How long does it take to generate an AI scene in 2026?
For video clips, standard AI generators produce 3 to 12 seconds of footage in under 60 seconds. For full physics-augmented 3D interactive scenes, current systems complete generation in 10 to 30 minutes, compared to days or weeks with manual design.