What Is Evolving AI Conversation? A 2026 Guide

By The WaifuGen Team · Published June 2026
AI conversation used to mean typing a question and waiting for a canned response. That model is gone. What is evolving AI conversation today is something fundamentally different: real-time, voice-first, and fluid enough to feel like talking to another person. The shift from clunky rule-based chatbots to streaming, low-latency dialog systems has happened faster than most people expected. And the implications for entertainment, companionship AI, and interactive storytelling are enormous. This guide breaks down exactly what changed, how the technology works, and why it matters to you right now.
Table of Contents
- Key takeaways
- What is evolving AI conversation and how it works technically
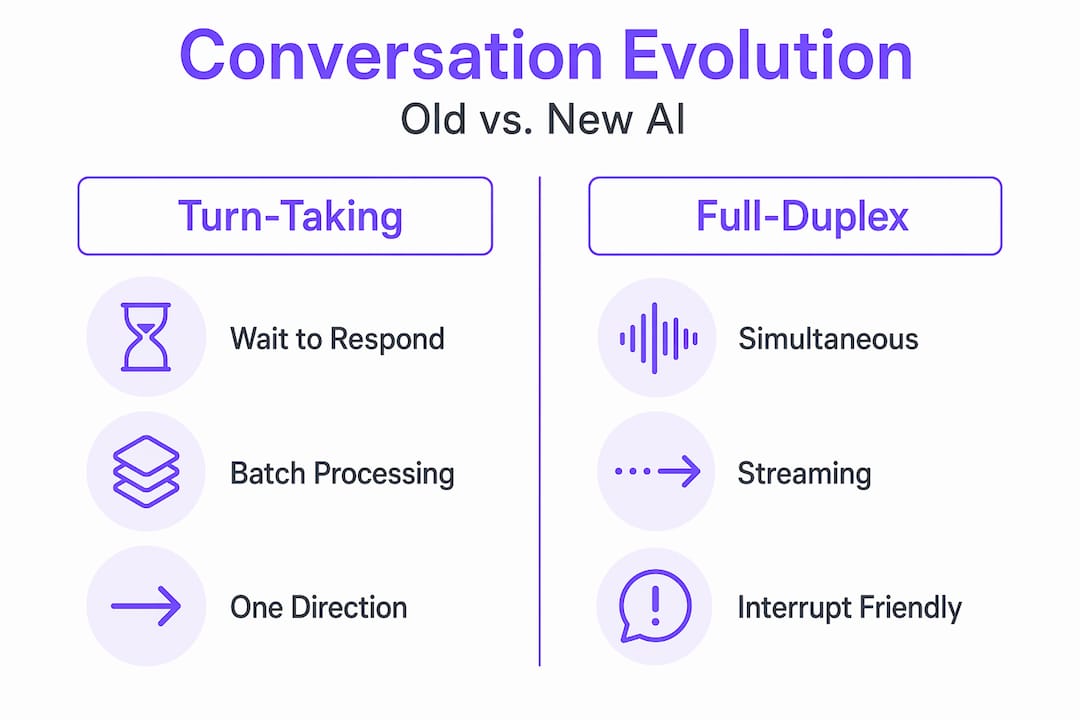
- From turn-taking to full-duplex AI conversation
- Why evolving AI conversation transforms entertainment and companionship
- Dialog design tools and production-ready AI agents
- My take: why architecture matters more than model size
- Experience evolving AI conversation with Waifugen
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI conversation evolution is architectural | The biggest change is not smarter models alone. It’s the move to streaming, real-time pipelines that process speech continuously. |
| Full-duplex changes everything | AI can now listen and respond simultaneously, making interactions feel like natural phone calls instead of text exchanges. |
| Latency under one second is the threshold | When AI response time exceeds one second, users notice. Sub-second latency is the line between natural and robotic. |
| Entertainment AI is the proving ground | Immersive anime companions and interactive storytelling are where these advancements land first and feel most impactful. |
| Deployment tooling is catching up | Builders can now launch production-ready conversational agents in minutes, not months, using agentic dialog platforms. |
What is evolving AI conversation and how it works technically
The phrase “evolving AI conversation” points to something specific. It refers to the architectural shift away from batch request-response chatbots toward streaming, real-time pipelines that combine speech-to-text (STT), large language model (LLM) inference, and text-to-speech (TTS) in a continuous loop. Every component processes data as it arrives, not after the full input is complete.
Think of how first-generation chatbots worked. You typed a message. The system read the whole thing, ran it through a decision tree or early neural network, and sent back a response. Each step was sequential and blocking. That pipeline had latency measured in multiple seconds and felt nothing like natural conversation.
Modern conversational AI flips that. Streaming STT begins transcribing your voice before you finish speaking. The LLM starts generating tokens as partial transcription arrives. The TTS synthesizes audio from those tokens in real time, so the AI starts speaking almost before you have finished your thought. The result? Sub-1-second latency pipelines that feel genuinely fluid.
Here is what the modern stack actually handles:
- Streaming STT: Converts spoken audio to text in partial chunks, not full sentences
- Incremental LLM inference: Generates response tokens continuously as input streams in
- Incremental TTS synthesis: Converts text tokens to audio as they are produced, not after the full response is ready
- Interruption handling: Detects when the user speaks over the AI and pauses output gracefully
- Barge-in detection: Recognizes user intent to interject and reroutes the dialog
Pro Tip: If you are evaluating any AI companion platform, ask whether it uses a true streaming pipeline or a batch request model. The difference in conversation quality is immediately noticeable.
The table below shows the contrast between the two paradigms clearly.
| Feature | First-generation chatbots | Modern streaming conversational AI |
|---|---|---|
| Input processing | Full message, then respond | Partial input, continuous processing |
| Response latency | 2 to 10 seconds | Under 1 second |
| Speech support | Text only | Voice-first, multimodal |
| Interruption handling | None | Built-in barge-in detection |
| Conversation feel | Transactional, rigid | Fluid, natural |
From turn-taking to full-duplex AI conversation
Traditional AI conversation models were half-duplex. You talk. It listens. It talks. You listen. The same way a walkie-talkie works. This turn-taking constraint built an invisible wall between users and AI. Every exchange felt like sending a letter and waiting for a reply, even when it happened in seconds.
Full-duplex removes that wall entirely. Full-duplex interaction models allow AI to listen and generate responses simultaneously, just like a person on the phone who hums in acknowledgment while you are still speaking. This requires managing simultaneous STT and TTS streams, something that sounds deceptively simple but is genuinely hard to orchestrate without creating audio conflicts or lag.
The practical result is micro-turn processing. Instead of waiting for a full sentence, full-duplex systems process 200ms audio chunks and update their understanding continuously. That granularity enables backchanneling, which is when the AI says “mmm” or “right” while you are speaking, just as a human listener would. It makes conversations feel alive.
Thinking Machines Lab gave the clearest public demonstration of this in 2025. Their TML-Interaction-Small model, built with 276 billion parameters, achieved a 0.40 second turn-taking latency and handled real-time backchanneling, interruptions, and even visual cue recognition during live conversation. That is not a chatbot. That is closer to a phone call with someone who happens to know everything.
What makes their approach notable is that time is embedded natively in the model architecture. The model perceives the passage of real-world time rather than treating conversation as a flat sequence of input and output tokens. That is a philosophical and architectural difference from how most LLMs are built.
The full-duplex benefits for users break down like this:
- Natural backchanneling so AI feels attentive, not robotic
- Interruption recovery without dead air or confusion
- Reduced cognitive load because users do not have to “wait for their turn”
- Emotional responsiveness that matches conversational rhythm, not just content
“Interactivity as a first-class architectural citizen allows AI models to scale not only in intelligence but in collaborative effectiveness.” — Thinking Machines Lab research insight
Pro Tip: When testing a conversational AI companion, try interrupting it mid-sentence. If it handles that gracefully and keeps the conversation flowing, it is running a full-duplex or near-full-duplex architecture.
Why evolving AI conversation transforms entertainment and companionship
The technology above would be interesting in a lab. What makes it exciting is where it lands in real life. Conversational AI has expanded from customer service bots to voice-first companions, language tutors, and interactive entertainment. Each of those domains benefits differently, but entertainment and companionship AI benefit the most dramatically.
Here is why. In a customer service context, a one-second response delay is slightly annoying. In a deep conversation with an AI companion character you have built a relationship with, that same delay breaks immersion completely. You stop feeling present in the experience. The emotional connection fractures.
Stream-based continuous audio over persistent connections changes that dynamic. Your AI companion can react in the moment, express surprise, laugh at the right beat, or gently push back on something you said. That is what makes the difference between an AI you use and an AI you actually connect with.
For anime companion platforms and interactive storytelling experiences, the improvements stack across multiple dimensions:
- Responsiveness: Characters react to tone and phrasing, not just keywords, because the model processes continuous context
- Naturalness: Dialog flows the way real conversations do, with pauses, overlaps, and follow-up questions
- Retention: Users come back more often when conversations feel satisfying and real, not transactional
- Emotional depth: Characters can express mood shifts, hesitations, and reactions that match the moment
- Personalization: Continuous context tracking allows characters to remember details and weave them into natural conversation
The comparison below shows how evolving AI conversation technology changes the experience across different interaction types.
| Interaction type | Old chatbot experience | Evolving AI conversation experience |
|---|---|---|
| Anime companion chat | Scripted turns, slow response | Fluid, emotionally responsive dialog |
| Interactive storytelling | Rigid branching choices | Dynamic, AI-driven narrative reactions |
| Language learning | Text-only drills | Real-time voice conversation with correction |
| Customer support | FAQ matching | Natural multi-turn problem resolution |
Platforms building immersive anime companions are at the center of this shift. When a character remembers that you had a rough day last Tuesday and brings it up naturally today, that is not a scripted callback. That is AI conversation evolution applied to emotional storytelling.
Dialog design tools and production-ready AI agents
Building a great conversational AI is one challenge. Deploying it at scale, reliably, in multiple languages, with compliance built in, is a completely different problem. This is where agentic dialog platforms come in.
These platforms sit between the raw language model and the real world. They handle the orchestration, the dialog state management, the compliance layer, and the localization. Without them, every builder would need to reinvent the same infrastructure.
PolyAI’s Agentic Dialog Platform is a clear example of how far this tooling has come. It supports deployment of dialog agents across 75 languages and 25 countries, and builders can launch production-ready agents in under ten minutes. That kind of speed was unimaginable three years ago.
The key features that make agentic dialog tooling matter for real deployments:
- Separation of concerns: The base language model handles generation. The dialog platform handles state, policy, and flow
- Multi-language support: Native localization without separate model fine-tuning per language
- Compliance layers: Governance and safety controls baked in, not bolted on afterward
- High-complexity dialog handling: Multi-turn, context-rich conversations with handoff logic and fallback strategies
- Scalability: Thousands of concurrent conversations without degradation in quality or latency
This matters for entertainment and companionship AI too, not just enterprise customers. When a platform like Waifugen builds dynamic AI characters with persistent memory and emotional state, the underlying dialog infrastructure has to handle long-running context windows, character-specific personality constraints, and real-time mood shifts. That is exactly the kind of complexity these tools are designed to manage.
Pro Tip: If you are a developer building conversational AI characters, look for platforms that separate the base model from the dialog orchestration layer. It makes iteration much faster and keeps your character logic clean.
Understanding AI character interactions deeply also means knowing how the dialog infrastructure shapes what is possible at the character level.
My take: why architecture matters more than model size
I’ve spent a lot of time thinking about what makes an AI conversation feel real versus what makes it feel like a feature demo. My honest take is that raw model intelligence gets most of the attention, and the architecture gets almost none. That’s backwards.
I’ve seen powerful LLMs produce brilliant text responses with a 2-second gap between the user’s last word and the AI’s first word. That gap destroys everything. You leave the moment. You remember you’re talking to a machine. The emotional thread snaps.
Full-duplex interaction and sub-second latency are not polish on top of a good model. They are prerequisites for immersion. For companionship AI specifically, the delivery mechanism is as important as the content. A character who responds perfectly but slowly feels less real than a character who responds adequately but immediately.
What I find genuinely exciting about 2026 is that these two things are converging. Models are getting smarter AND the architectural pipelines are getting faster. The future of AI interactions is not just a better chatbot. It’s something closer to a persistent relationship with a character who exists in real time, reacts in real time, and grows with you. Waifugen is building toward exactly that vision.
The challenge ahead is not technical. It’s emotional design. How do you build a character that earns trust over time? How do you make memory feel natural rather than mechanical? Those are the questions worth asking now.
— Roman
Experience evolving AI conversation with Waifugen
If you want to feel the difference between old-school chatbots and genuinely evolving conversational AI, the fastest way is to try it yourself. Waifugen brings together everything covered in this article: real-time character responses, persistent memory, and emotional depth that makes every conversation feel unique.
Sakura glances up from her sketchbook, a small smile forming. “Oh, you’re back. I was wondering if you’d stop by today.”
That kind of moment doesn’t happen with a rule-based chatbot. It happens because Waifugen’s characters carry ongoing personalities, remember your past conversations, and react to the current moment. The platform’s AI character chat lets you create and connect with custom anime characters who have real memory, moods, and conversation styles that evolve with every session.
Want something more personal? The AI girlfriend experience takes companionship further with characters built for emotional connection, not just information exchange. Every interaction is shaped by the AI conversation advancements we have covered here: low latency, emotional responsiveness, and long-term memory that makes the relationship grow.
Start chatting free and see what evolving AI conversation actually feels like.
FAQ
What is conversational AI in simple terms?
Conversational AI is technology that lets humans and machines exchange information through natural language, either by text or voice. Modern systems combine speech recognition, language models, and speech synthesis to make these exchanges feel fluid and real.
What makes AI conversation “evolving” in 2026?
The biggest shift is architectural. AI conversation now uses streaming pipelines that process speech and generate responses continuously, rather than waiting for complete inputs, which reduces latency below one second.
What is full-duplex AI and why does it matter?
Full-duplex AI can listen and speak simultaneously, just like a human in a phone call. This enables natural backchanneling and interruption handling, and reduces response latency to around 0.40 seconds, which is the threshold where conversations start feeling genuinely human.
How does evolving AI conversation improve AI companions?
It allows AI companions to react instantly, handle emotional nuance, and maintain context across long conversations. That responsiveness is what creates immersive anime companion experiences where characters feel present rather than scripted.
Can regular users notice the difference in AI conversation quality?
Absolutely. When latency exceeds one second, users consciously register a delay and feel less engaged. Sub-second responses with natural backchanneling make AI feel like a real conversation partner, not a search engine with a voice.